一些算法举例
字符串
复原IP地址
给定一个只包含数字的字符串,复原它并返回所有可能的IP地址格式。
有效的IP地址正好由四个整数(0到255之间组成),整数之间用’.’分隔。
- 示例
输入: "25525511135"
输出:["255.255.11.135", "255.255.111.35"]
- 思路
回溯法
1、一开始,字符串的长度小于 4 或者大于 12 ,一定不能拼凑出合法的 ip 地址(这一点可以一般化到中间结点的判断中,以产生剪枝行为);
2、每一个结点可以选择截取的方法只有 3 种:截 1 位、截 2 位、截 3 位,因此每一个结点可以生长出的分支最多只有 3 条分支;
根据截取出来的字符串判断是否是合理的 ip 段,这里写法比较多,可以先截取,再转换成 int ,再判断。我采用的做法是先转成 int,是合法的 ip 段数值以后,再截取。
3、由于 ip 段最多就 4 个段,因此这棵三叉树最多 4 层,这个条件作为递归终止条件之一;
- 解法
func restoreIpAddresses(_ s: String) -> [String] {
//回溯法
var res:[String]=[]
var tmp:[String]=[]
let chs:[Character]=[Character](s)
backTrace(&res,&tmp,chs,0,0)
return res
}
func backTrace(_ res:inout [String],_ tmp:inout [String],_ chs:[Character],_ ind:Int,_ has:Int){
if ind == chs.count && has == 4{
var str:String=""
for i in tmp{
str += i+"."
}
str.removeLast()
res.append(str)
return
}
if (has == 4 && ind < chs.count) || (ind == chs.count && has < 4){return}
for i in ind...ind+2{
if i >= chs.count{break} //确保i是一个有效的下标
if i > ind && chs[ind] == "0"{break}
let str:String=String(chs[ind...i])
if str.count == 3 && str > "255"{continue} //长度为1和2的数都可以,为3的话需要筛选
tmp.append(str)
backTrace(&res,&tmp,chs,i+1,has+1)
tmp.removeLast()
}
}
- 结果
let ress = solution.restoreIpAddresses(“25525511135”)
print(ress)
[“255.255.11.135”, “255.255.111.35”]
字符串相乘
- 示例
输入:num1="123",num2="456"
输出:"56088"
num1,num2均不以0开头,除非是数字0本身
- 思路
第i位和第j位相乘,结果会在第i+j上面,如果有进位,则i+j-1上也有,结果是倒序的
- 解法
代码实现:
func multiply(_ num1: String, _ num2: String) -> String {
if Int(num1) == 0 || Int(num2) == 0 {return "0"}
var result = ""
var resultArray: [Int] = [Int].init(repeatElement(0, count: num1.count+num2.count))
//这两个for执行完,结果数组里面是未处理过进位的结果
for i in (0..<num1.count) {
for j in 0..<num2.count {
let c1 = Int(String(num1[i]))!
let c2 = Int(String(num2[j]))!
let res = c1*c2
resultArray[i+j] += res
}
}
//处理进位
var carrys = 0
for i in (0..<resultArray.count).reversed() {
if resultArray[i] == 0 {
continue
}
let tmp = resultArray[i]+carrys
carrys = tmp/10
resultArray[i] = tmp%10
}
//最后一位如果是0,则需要舍弃
let end = resultArray.last!==0 ? resultArray.count-1 : resultArray.count
for i in 0..<end {
result += String(resultArray[i])
}
return result
}
- 测试
print(solution.multiply("123", "3128"))
- 结果
384744
字符串s1和s2,判断s2中是否包含s1的排列
- 示例
输入:"abo"和"eidboammnj"
输出:true
如果是"abb"则false,字符串都是小写,长度1-10000
- 思路
采用窗口滑动法,从开始的空窗口从左向右滑动
- 解法
代码实现:
//保证了字符串都是小写字母,97是小写的a,65是大写的A
func checkInclusion(_ s1: String, _ s2: String) -> Bool {
if s1.isEmpty || s2.isEmpty {return false}
guard s1.count <= s2.count else {
return false
}
func allZero(_ counts: [Int]) -> Bool {
for i in 0 ..< 26 {
if counts[i] != 0 {
return false
}
}
return true
}
let chars1 = Array(s1.unicodeScalars)
let chars2 = Array(s2.unicodeScalars)
let len1 = chars1.count
let len2 = chars2.count
var counts = [Int](repeatElement(0, count: 26))
//可以简单理解有两个同时滑动的窗口,都向右滑,上面一个窗口后面会为空
for i in 0 ..< len1 {
//s1从右边滑进的+1,从右边滑出的-1
counts[Int(chars1[i].value - 97)] += 1
//s2从右边滑进的-1,从右边滑出的-1
counts[Int(chars2[i].value - 97)] -= 1
}
if allZero(counts) {return true}
//因为都是s2,所以只看滑进还是滑出
for i in len1 ..< len2 {
//从右边滑进,-1
counts[Int(chars2[i].value - 97)] -= 1
//从右边滑出,+1
counts[Int(chars2[i - len1].value - 97)] += 1
if allZero(counts) {return true}
}
//窗口的大小是短串的长度,必须要这样,否则肯定是false
return false
}
有一个字符串和一组子字符串,请返回覆盖率最高,单词最多的子字符串列表
示例:
字符串: abcdefg
子字符串: ((ab,0, 1), (cd, 2, 3),(efg,4, 6), (abc,0,2),(abcd, 0, 3), (cdef, 2, 5))
期望: {ab, cd, efg}
- 分析
最长不重复子串
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。 示例:
输入:"adbdeacdmmm"
输出:5
解释:因为无重复的最长子串是"bdeac"或者"eacdm"
- 分析
首先本体如果使用两层for循环当然可以轻松搞定,但是时间复杂度也是O(n^2),显然不是很满意,所以需要想个法子将复杂度调整到O(n)。 因为是子串,不是子序列,所以肯定是一串连续的字符区域。头设定为start,尾设定为end。那么在仅仅遍历一遍的情况下,start是会不断往后涨的,end就是当前遍历的位置。 1. 如果当前遍历的字符在start后面没有出现过,则接着遍历,start往后移 2. 如果当前遍历的字符已经出现了(这里可以使用hash表记录,key是character,value是index),则说明肯定有字符重复,需要将start移到这个重复字符处,也就是遍历的字符上一次出现的位置的下一个位置(index) 3. 在这个过程中,时刻更新最大长度
- 解法
代码实现:
//code1
extension String {
subscript(_ i: Int)->Character {
get {return self[index(startIndex, offsetBy: i)]}
}
}
code1是为了给string添加subscript操作,真正功能代码是:
//code2
func lengthOfLongestSubstring(_ s: String) -> (Int, String?) {
if s.isEmpty {
return (0, nil)
}
var maxLength = 0
var start = maxLength
var retString: String? = " "
var hashTable: Dictionary<Character, Int> = [Character:Int]()
for i in 0..<s.count {
if hashTable.keys.contains(s[i]) && hashTable[s[i]]! >= start {
start = hashTable[s[i]]!+1
}
hashTable[s[i]] = i
maxLength = max(maxLength, i+1-start)
}
return (maxLength, retString!)
}
当然code2实际上只是输出长度并没有输出子字符串,我们尝试着输出长度和子字符串,其实就是在code2的基础上稍微改一下:
//code3
func lengthOfLongestSubstring(_ s: String) -> (Int, String?) {
if s.isEmpty {
return (0, nil)
}
var maxLength = 0
var start = maxLength
var retString: String? = " "
let strArray = Array(s)
var hashTable: Dictionary<Character, Int> = [Character:Int]()
for i in 0..<s.count {
if hashTable.keys.contains(s[i]) && hashTable[s[i]]! >= start {
start = hashTable[s[i]]!+1
}
hashTable[s[i]] = i
//此处就是获取子串,由于会一直遍历到最后,所以如果有多个相等长度的子串,会停留在最后一个子串,返回
if i+1-start >= maxLength {
let subArr = strArray[start..<i+1]
let subStr: String = subArr.map{String.init($0)}.joined()
retString = subStr
}
maxLength = max(maxLength, i+1-start)
}
return (maxLength, retString!)
}
示例代码如下:
var solution = Solution()
var turple1 = solution.lengthOfLongestSubstring("adbdeacdmmm")
print(turple1)
以“adbdeacdmmm”为例,则长度为5,子串为:”bdeac”或者”eacdm”,但是由于“eacdm”在后面,所以输出的是“eacdm” 可以看到:
最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串”” 示例:
输入:["flower","flow","flight"]
输出:"fl"
说明
所有的输入只包含小写字母a-z
- 解法一
暴力循环法,从题目可知:最长公共前缀的长度一定是字符串数组中长度最短的哪个字符串
- 首先找出长度最短的字符串str,比如str=”abcf”。
- 以此对’abcf’,’abc’,’ab’,’a’进行筛选,判断哪个是所有的其他字符串的前缀。
- 解法二
看下图:
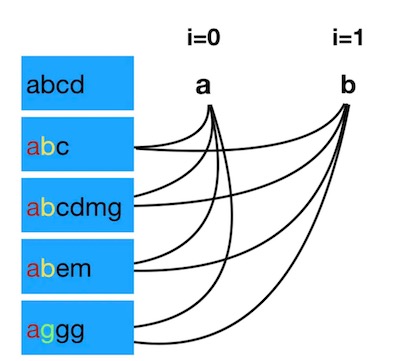
对str[0]按照字符遍历,与其他字符串以此比较对应位置上的字符,并记录查找位置,如果找到不相等或者对应字符串的长度到了限制,就找到了。
代码如下:
func longestCommonPrefix(_ strs: [String]) -> String {
if strs.count <= 0 {
return ""
}
if strs.count == 1 {
return strs[0]
}
let str = strs[0]
for i in 0..<str.count {
let c: Character = str[i]
for j in 1..<strs.count {
if i == strs[j].count || c != strs[j][i] {
let rightIndex = strs[0].index(strs[0].startIndex, offsetBy: i)
return String(strs[0][strs[0].startIndex..<rightIndex])
}
}
}
return strs[0]
}
测试:
let strs2: [String] = ["abcdfj", "abc", "abcmnihiuh", "abcmunh"]
let str2: String = solution.longestCommonPrefix(strs2)
print(str2)
结果:
abc